《 SiP 前世今生 》系列文章由 Cadence 專欄作者 Paul McLellan 撰寫。該系列共三篇文章,前兩篇聚焦於 SiP 的驅動因素與技術發展,最後一篇內容重在闡明SiP的設計挑戰與解決方案。
超越摩爾 ( Moore and More )
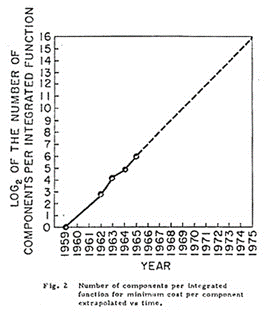
50 多年來,半導體業一直受益於摩爾定律。但是如今,半導體等比例縮小的時代已經結束。摩爾定律主要是作為一條經濟法而存在——即積體電路上可容納的電晶體數量,約每隔幾年便會增加一倍。當然,是技術的發展使之成為現實;直到幾年前,這一定律依然適用。高層次的經濟主張是:每一代工藝將同一領域的電晶體數量增加一倍,成本僅增加 15%,從而為每個電晶體節省 35% 的成本。但是因為當今的工藝愈發複雜,加之建造一個工廠的資本投入非常大(每台 EUV 光刻機將耗資 1 億美元),導致每一代電晶體都更加昂貴。因此我們發展出一個從 7nm 到 5nm 再到 3nm 的工藝進程以及之後幾代的進程。但從經濟角度來看,這些工藝不僅會像過去幾十年來那樣增加每個晶圓的成本,更會增加每個電晶體的成本。
戈登‧摩爾 (Gordon Moore) 很早就預料到這一天會到來,他表示從未想過摩爾定律會持續 50 多年。在幾年前美國 SEMICON West 的視頻採訪中,當被問及他想因什麼而被銘記時,戈登表示:「除了摩爾定律什麼都不想。」但在《電子學》的原創論文中,他說:
「事實可能會證明,用較小的功能模組構建大型系統將更加經濟,而這些較小的功能模組是分開封裝和互連的。 」
那一天已經到來。
另一個已存趨勢是製造複雜的封裝,即在一個封裝中放置多個晶片的方法已變得更加經濟。像所有大規模生產技術一樣,這在很大程度上依靠大規模生產得來的經驗。大型微處理器使用 interposer 技術;較小的(在電晶體數量和物理性能方面)通訊晶片則一直使用扇出型晶片封裝(FOWLP)技術。由於智慧手機每年的出貨量約為 15 億部,這意味著任何一款型號的手機都可能出貨量達到數億部,提供了大量的生產經驗。
考慮到以上因素,發展的平衡已經改變。在同一個晶片上製造大量電晶體,還是製造更小的晶片並將它們封裝在一起,在經濟上是一個複雜的決定。曾經,至少對於大型設計來說,經濟上總是偏向單一的系統級晶片;但是現在,越來越多的事實證明天平已向複雜封裝傾斜。
晶片尺寸 (Die Size)
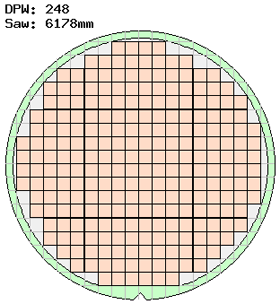
大晶片比小晶片產量低。如果致命的缺陷隨機分佈在晶片上,那麼大晶片則更有可能存在缺陷。同時,大晶片的晶片邊緣也有更多的浪費區域,因為晶圓更多而沒有空間來放置晶片。過去,儘管存在上述缺點,構建大的系統級晶片 (SoC) 也比構建單獨的晶片後再將它們封裝在一起更為經濟。但是現在,構建小晶片卻更為划算,特別是當一個完整的系統可以使用同一個晶片的多個副本時。以這種方式構建一個高級多核微處理器或一個可程式設計閘陣列並不太具挑戰性(顯然毫無規律的巨大晶片無法利用這一點)。
超大設計還有一個問題:光刻工藝具有最大倍縮光罩尺寸 (reticle size)。如果設計比這更大,那麼進行分割是唯一的選擇。
然而事實並非如此。Cerebras 公司製造了世界上最大的單晶片,是可以放在 300mm 晶片上的最大的正方形。這種方法需要對切割線的互連進行特殊處理(並沒有將晶片分開)。這也需要很強的一致性,因為所有的晶片都必須是相同的。然而,對於大多數設計來說,這種方法並不奏效。但是我們可以用 Microvax 晶片進行晶圓級整合,只需要在晶片上得到電源、地和乙太網三個信號即可。也許 Cerebras 的方法將會得到更廣泛的應用。
保持記憶體緊密
所有高性能處理器,無論是 CPU、GPU、深度學習處理器還是其他處理器,都需要大記憶體,以作為緩存或者直接存儲(大)資料。大多數計算中的大量功耗只是簡單地搬移資料,而不是進行實際計算。整體計算中的大多延遲也來自於這種搬移,所以顯而易見地,我們需使記憶體更加靠近處理器。這將降低功耗,提高性能。
最明顯的方法是把動態隨機存取記憶體 (DRAM) 和處理器放在同一個晶片上,但是這存在兩個問題。首先,是前文討論的晶片尺寸限制問題。其次,雖然可以混合動態隨機存取記憶體和邏輯處理,但成本較高。我們不能只用幾個光罩就把動態隨機存取記憶體添加在邏輯晶片上。
解決該問題的最早的方法被稱為封裝內封裝(package-in-package,PiP)。該術語區別於封裝上封裝(package-on-package,PoP):在 PoP 中,兩個球柵陣列(BGA)封裝實際上是堆疊在一起的。兩個晶片,如智慧手機應用處理器和動態隨機存取記憶體,被放在同一個封裝中,並且全部由引線鍵合,以避免出現像矽通孔(TSv)一樣的複雜問題。這個方法已應用在智慧手機上多年。
對於記憶體不足的高性能計算,則通常需要存取幾個高頻寬記憶體(HBM 或 HBM2)。這些晶片由一個邏輯晶片和四或八個堆疊在頂部的動態隨機存取記憶體晶片組成,並都與矽通孔相連接。其實這已經是一個 3D 積體電路,儘管其本身並不具有很大的用處。然後將該電路放在處理器旁邊的 interposer 上。下圖是 AMD 公司的 Fuji 產品設計解析,Fuji 是最早使用這種方法的設計之一。
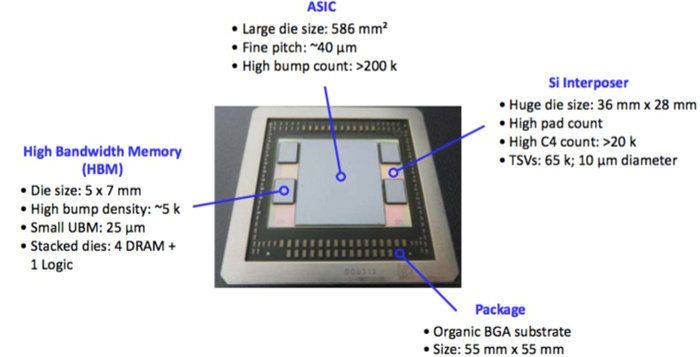
還有一個 JEDEC 寬輸入/輸出標準,用於標準化高頻寬記憶體(因此記憶體不依賴於設計),然後將帶矽通孔的記憶體放在邏輯晶片的頂部。由於寬輸入/輸出有 1000 個或更多引腳,它可以獲得非常高的頻寬,而不需要 DDR 介面上的所有 SerDes。
這種方法也用於互補金屬氧化物半導體圖像感測器(CIS)。感測器不是嚴格意義上的記憶體,而是類似記憶體:感測器的光線會穿過晶片的背面。這樣,互連就不會有所妨礙。感測器變薄以透光,再將感測器進行翻轉。相關的邏輯晶片被設計成完全相同的尺寸,翻轉的感測器可以恰好地安裝其上。有時,第三個動態隨機存取記憶體晶片會放入堆疊的中間。下圖是三層的 Sony CIS 設計。

本篇內容至此結束,下一篇文章中我們將聚焦於 異質整合與 chiplets 的工藝技術與發展,請大家繼續關注。


譯文授權轉載出處
長按識別 QRcode,關注「Cadence 楷登 PCB 及封裝資源中心」

歡迎關注 Graser 社群,即時掌握最新技術應用資訊


